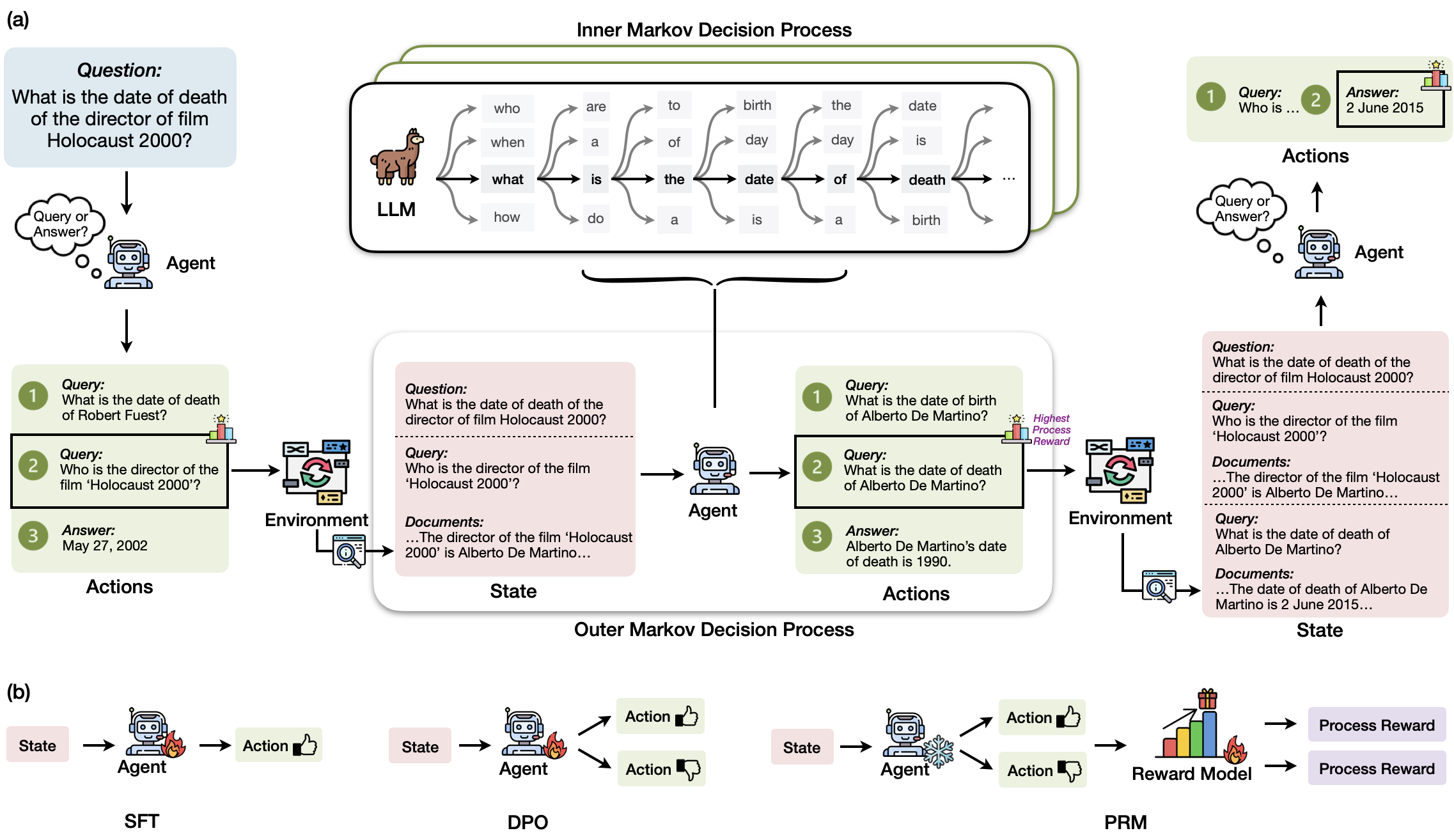
Retrieval-augmented generation (RAG) has shown great promise for knowledge-intensive tasks and recently advanced with agentic RAG, where language agents engage in multi-round interactions with external knowledge sources for adaptive information retrieval. However, existing agentic RAG methods often depend on ad-hoc prompt engineering and lack a unified optimization framework.
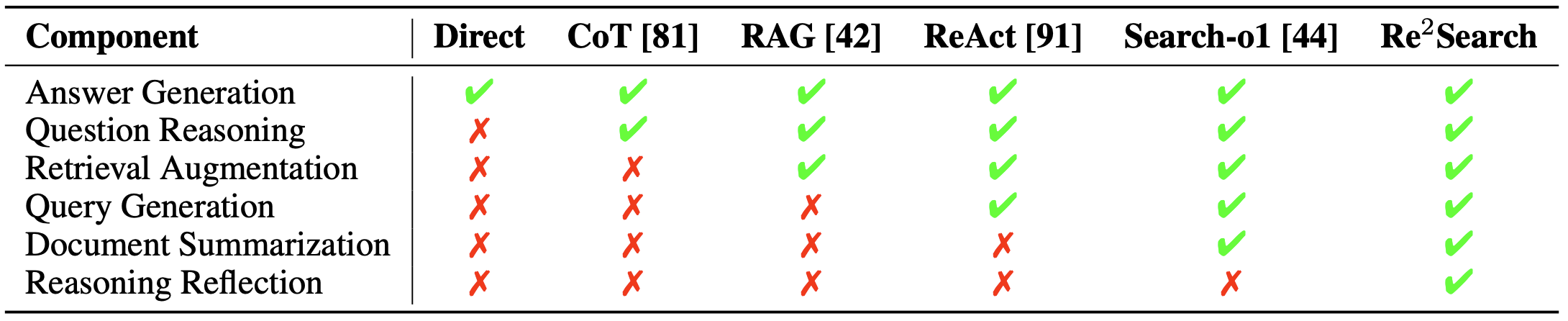
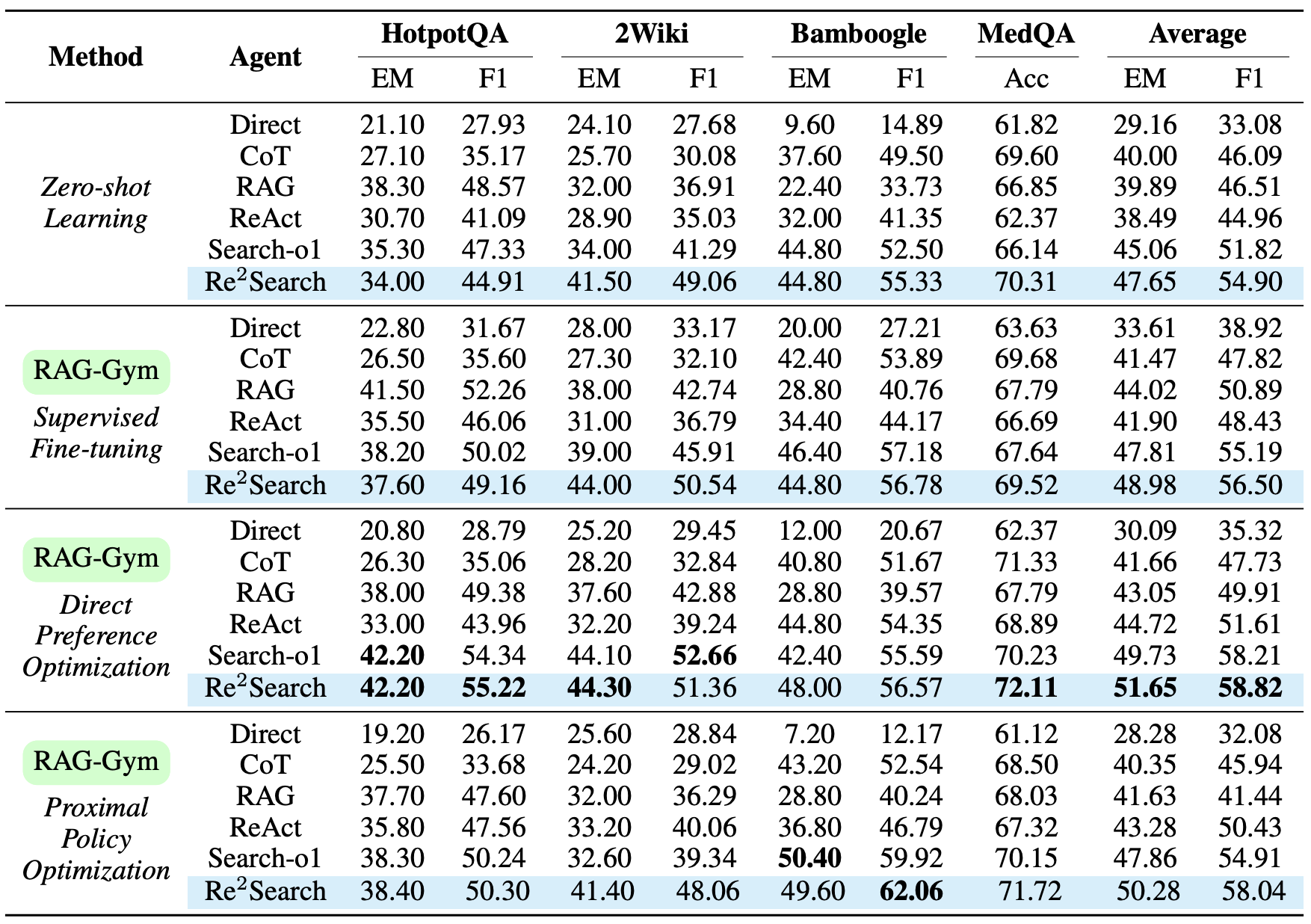
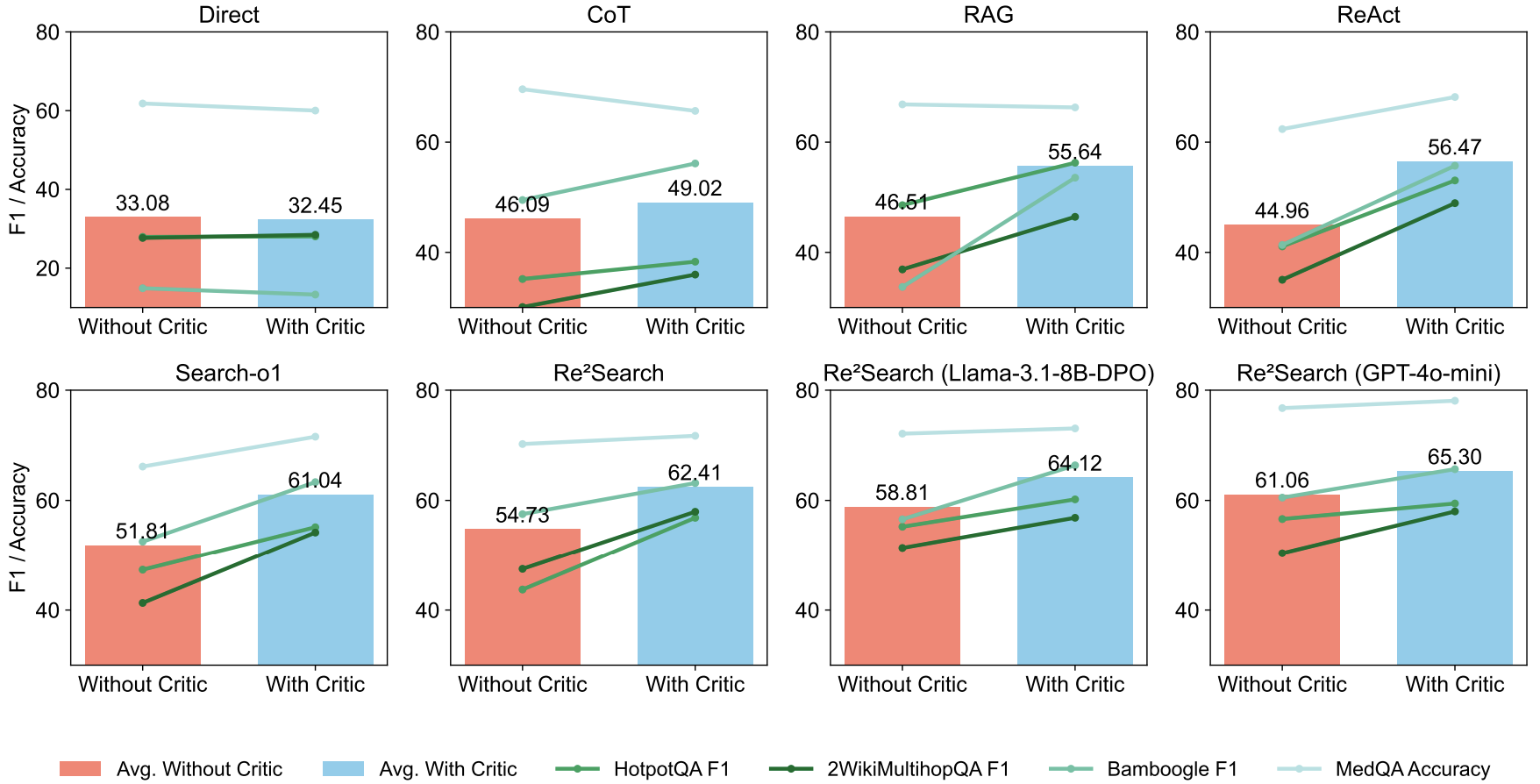
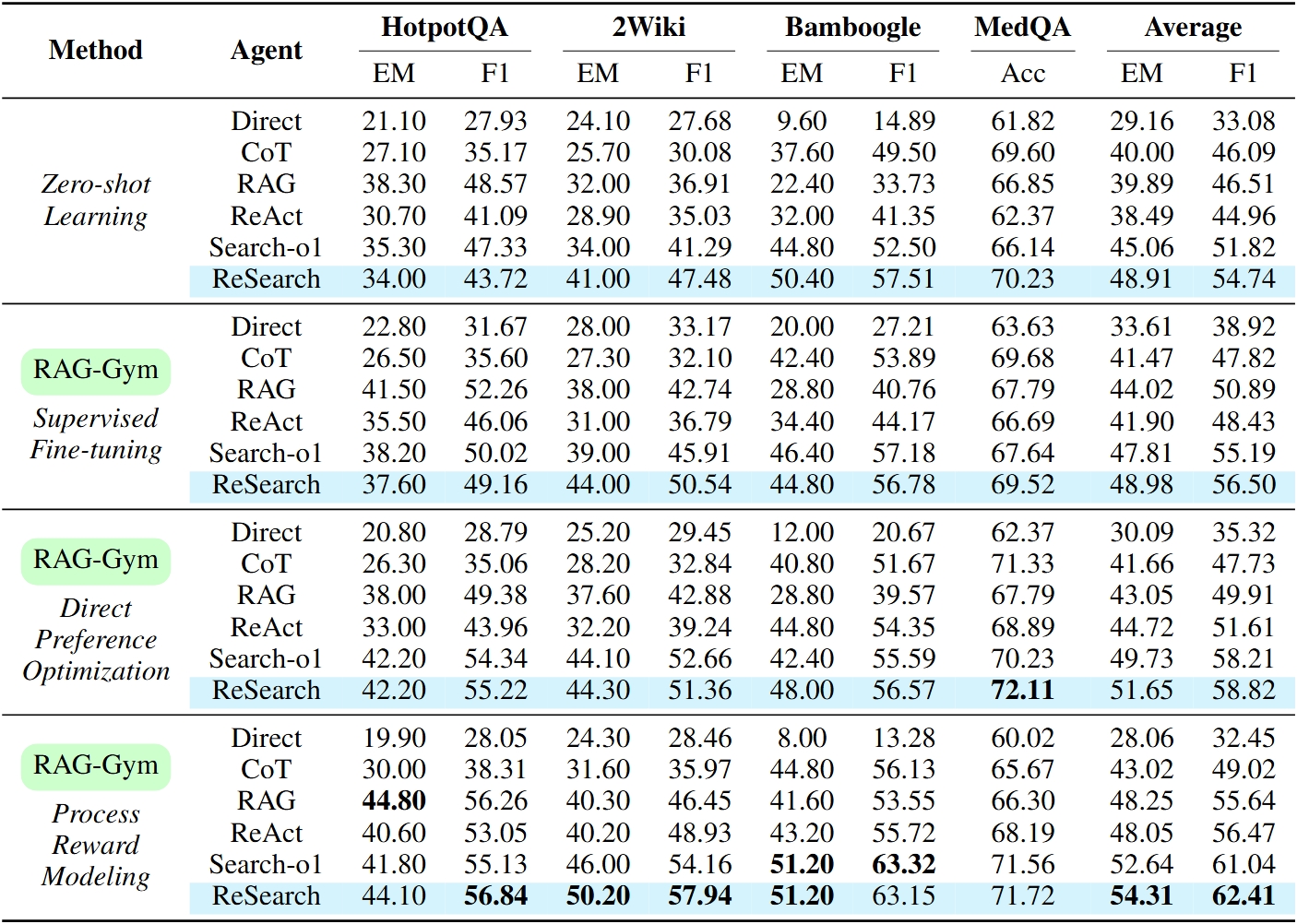
We introduce RAG-Gym, a comprehensive platform that systematically explores three optimization dimensions: (1) prompt engineering, (2) actor tuning, and (3) critic training. For prompt engineering, we propose Re²Search, a novel agent incorporating reasoning reflection that significantly outperforms standard prompts. In actor tuning, we evaluate three popular post-training algorithms with fine-grained process supervision and identify direct preference optimization as the most effective. We further demonstrate that a trained critic can enhance inference by selecting higher-quality intermediate reasoning steps.
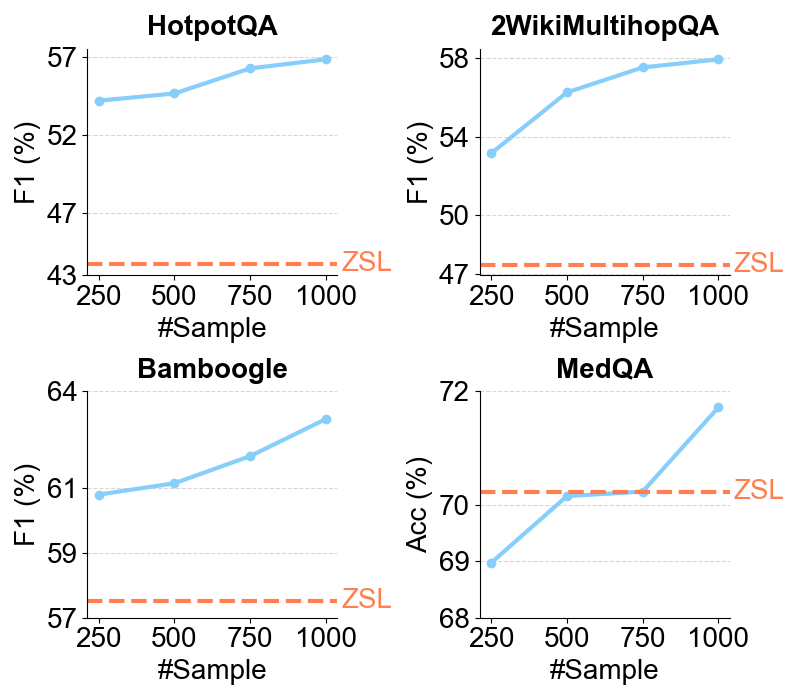
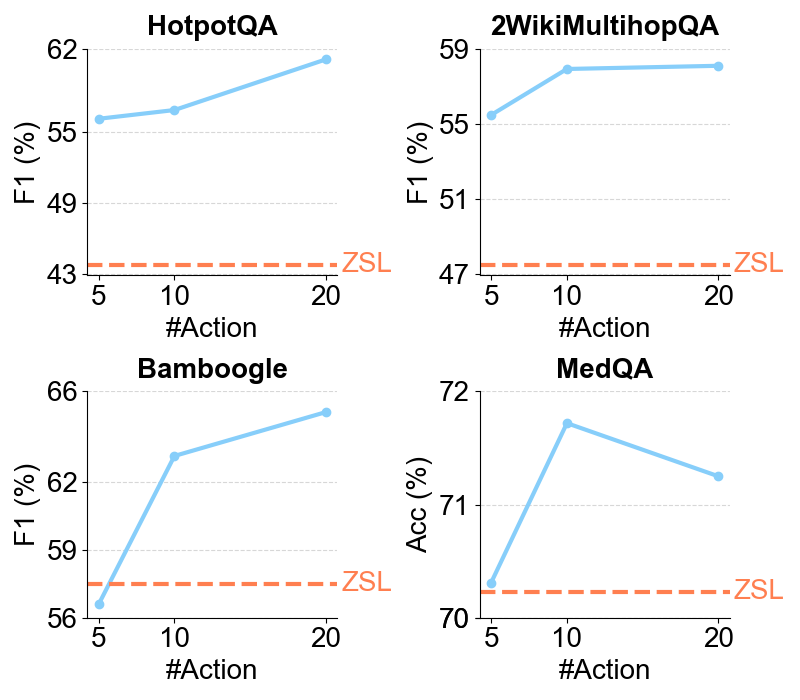
Together, these findings lead to the optimized Re²Search++ agent, which surpasses most recent methods like Search-R1 by a relative increase of 3.2% to 11.6% in average F1. Finally, we examine the impact of different reward sources and analyze scaling properties in training and inference, offering practical insights for agentic RAG optimization.